
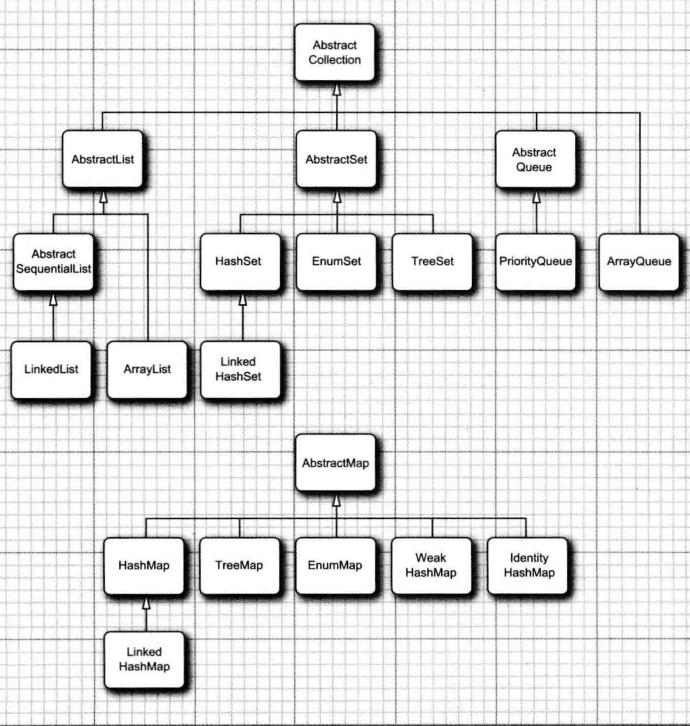
java集合实现类
实现类

arraylist
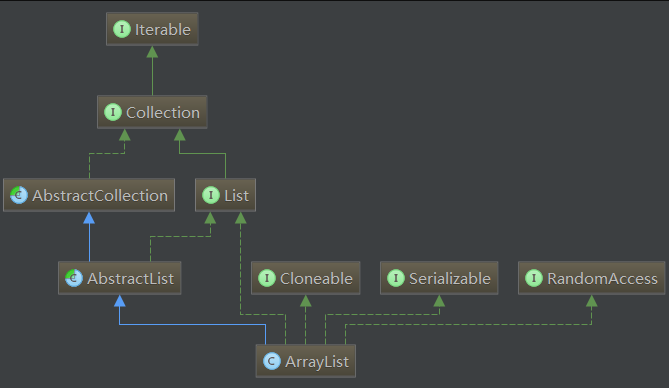
主要继承的接口如下:
1.Collection 接口: Collection接口是所有集合类的根节点,Collection表示一种规则,所有实现了Collection接口的类遵循这种规则
2.List 接口: List是Collection的子接口,它是一个元素有序(按照插入的顺序维护元素顺序)、可重复、可以为null的集合
3.AbstractCollection 类: Collection接口的骨架实现类,最小化实现了Collection接口所需要实现的工作量
4.AbstractList 类: List接口的骨架实现类,最小化实现了List接口所需要实现的工作量
5.Cloneable 接口: 实现了该接口的类可以显示的调用Object.clone()方法,合法的对该类实例进行字段复制,如果没有实现Cloneable接口的实例上调用Obejct.clone()方法,会抛出CloneNotSupportException异常。正常情况下,实现了Cloneable接口的类会以公共方法重写Object.clone()
6.Serializable 接口: 实现了该接口标示了类可以被序列化和反序列化,具体的 查询序列化详解
7.RandomAccess 接口: 实现了该接口的类支持快速随机访问
以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组,因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。
按照数组索引访问元素:get(int index)/set(int index)的性能很高,这是数组的优势。直接在数组末尾加入元素:add(e)的性能也高,但如果按索引插入、删除元素:add(i,e)、remove(i)、remove(e),则要用System.arraycopy()来移动部分受影响的元素,性能就变差了,这是数组的劣势。
ArrayList是线程不安全的,只能在单线程环境下,多线程环境下可以考虑用Collections.synchronizedList(List list)方法返回一个线程安全的ArrayList对象,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
1 | add(a); //增加元素 |
linkedlist
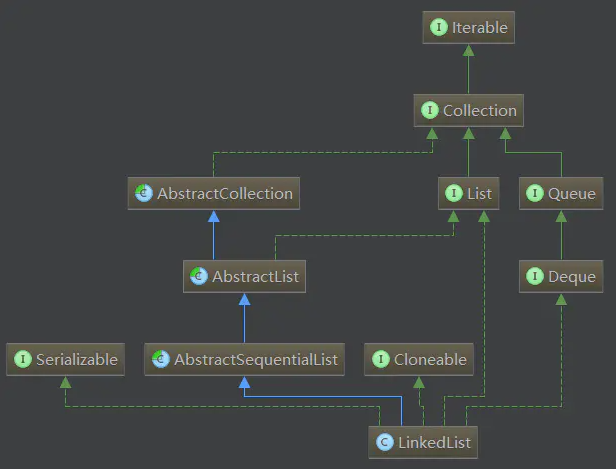
1.Collection 接口: Collection接口是所有集合类的根节点,Collection表示一种规则,所有实现了Collection接口的类遵循这种规则
2.List 接口: List是Collection的子接口,它是一个元素有序(按照插入的顺序维护元素顺序)、可重复、可以为null的集合
3.AbstractCollection 类: Collection接口的骨架实现类,最小化实现了Collection接口所需要实现的工作量
4.AbstractList 类: List接口的骨架实现类,最小化实现了List接口所需要实现的工作量
5.Cloneable 接口: 实现了该接口的类可以显示的调用Object.clone()方法,合法的对该类实例进行字段复制,如果没有实现Cloneable接口的实例上调用Obejct.clone()方法,会抛出CloneNotSupportException异常。正常情况下,实现了Cloneable接口的类会以公共方法重写Object.clone()
6.Serializable 接口: 实现了该接口标示了类可以被序列化和反序列化,具体的 查询序列化详解
7.Deque 接口: Deque定义了一个线性Collection,支持在两端插入和删除元素,Deque实际是“double ended queue(双端队列)”的简称,大多数Deque接口的实现都不会限制元素的数量,但是这个队列既支持有容量限制的实现,也支持没有容量限制的实现,比如LinkedList就是有容量限制的实现,其最大的容量为Integer.MAX_VALUE
8.AbstractSequentialList 类: 提供了List接口的骨干实现,最大限度地减少了实现受“连续访问”数据存储(如链表)支持的此接口所需的工作,对于随机访问数据(如数组),应该优先使用 AbstractList,而不是使用AbstractSequentailList类
• LinkedList()
构造一个空链表。
• LinkedList(Col 1ection<? extends E> elements)
构造一个链表, 并将集合中所有的元素添加到这个链表中。
• void addFirst(E element)
• void addLast(E element)
将某个元素添加到列表的头部或尾部。
• E getFirst()
• E getLast()
返回列表头部或尾部的元素。
• E removeFirst()
• E removeLast()
删除并返回列表头部或尾部的元素。
和arraylist比较
- 相同点
1.接口实现:都实现了List接口,都是线性列表的实现
2.线程安全:都是线程不安全的
- 不同点
1.底层实现:ArrayList内部是数组实现,而LinkedList内部实现是双向链表结构
2.接口实现:ArrayList实现了RandomAccess可以支持随机元素访问,而LinkedList实现了Deque可以当做队列使用
3.性能:新增、删除元素时ArrayList需要使用到拷贝原数组,而LinkedList只需移动指针,查找元素 ArrayList支持随机元素访问,而LinkedList只能一个节点的去遍历
1 | import java.util.Iterator; |
hashset
默认桶数是16,装填因子是0.75.
在 JavaSE 8 中, 桶满时会从链表变为平衡二叉树。如果选择的散列函数不当, 会
产生很多冲突, 或者如果有恶意代码试图在散列表中填充多个有相同散列码的值, 这样
就能提高性能。
import java.Iang.Object
int hashCode( )
返回这个对象的散列码。 散列码可以是任何整数, 包括正数或负数。equals 和 hashCode
的定义必须兼容,即如果 x.equals(y) 为 true, x.hashCodeO 必须等于 y.hashCodeO。
• HashSet( )
构造一个空散列表。
• HashSet( Collection<? extends E> elements )
构造一个散列集, 并将集合中的所有元素添加到这个散列集中。
• HashSet( int initialCapacity)
构造一个空的具有指定容量(桶数)的散列集。
• HashSet(int initialCapacity , float loadFactor )
构造一个具有指定容量和装填因子(一个 0.0 ~ 1.0 之间的数值, 确定散列表填充的百分比, 当大于这个百分比时, 散列表进行再散列)的空散列集。
treeset
实现 Comparable 接口和NavigableSet 接口,使用红黑树排序,有序集合。
将一个元素添加到树中要比添加到散列表中慢, 参见表 9-3 中的比较,但是, 与检查数
组或链表中的重复元素相比还是快很多。如果树中包含 n 个元素, 査找新元素的正确位置平
均需要 logn 次比较。 例如, 如果一棵树包含了 1000 个元素,添加一个新元素大约需要比较
10 次。

• TreeSet()
• TreeSet(Comparator<? super E> comparator)
构造一个空树集。
• TreeSet(Collection<? extends E> elements)
• TreeSet(SortedSets)
构造一个树集, 并增加一个集合或有序集中的所有元素(对于后一种情况, 要使用同样的顺序)。
NavigableSet 接口
• E higher(E value)
• E lower(E value)
返回大于 value 的最小元素或小于 value 的最大元素,如果没有这样的元素则返回 null。
• E ceiling(E value)
• E floor(E value)
返回大于等于 vaiue 的最小元素或小于等于 value 的最大元素, 如果没有这样的元素
则返回 null。
• E pollFirst()
• E pollLast
删除并返回这个集中的最大元素或最小元素, 这个集为空时返回 null。
• IteratordescendingIterator()
返回一个按照递减顺序遍历集中元素的迭代器。
SortedSet 接口
• Comparator <? super E> comparator ()
返回用于对元素进行排序的比较器。 如果元素用 Comparable 接口的 compareTo方法进行比较则返回 null。
• E firs()
• E 1ast()
返回有序集中的最小元素或最大元素。
linkedhashset
用来记住插人元素项的顺序。这样就可以避免在散列表中的项从表面上看是随机排列的。当条目插入到表中时,就会并人到双向链表中。和linkedhashmap类似……
链接散列映射将用访问顺序, 而不是插入顺序, 对映射条目进行迭代。每次调用 get 或 put, 受到影响的条目将从当前的位置删除, 并放到条目链表的尾部(只有条目在链表中的位置会受影响, 而散列表中的桶不会受影响。一个条目总位于与键散列码对应的桶中)。要项构造这样一个的散列映射表, 请调用
1 | LinkedHashMap<K, V>(initialCapacity, loadFactor, true) |
访问顺序对于实现高速缓存的“ 最近最少使用” 原则十分重要。例如, 可能希望将访问
频率高的元素放在内存中, 而访问频率低的元素则从数据库中读取。当在表中找不到元素项
且表又已经满时, 可以将迭代器加入到表中, 并将枚举的前几个元素删除掉。这些是近期最
少使用的几个元素。
甚至可以让这一过程自动化。即构造一个LinkedHashMap 的子类,然后覆盖下面这个方法:
1 | protected boolean removeEldestEntry(Map.Entry<K, V> eldest) |
每当方法返回 true 时, 就添加一个新条目,从而导致删除 eldest 条目。例如,下面的高
速缓存可以存放 100 个元素:
1 | Map<K, V> cache = new |
另外,还可以对 eldest 条目进行评估,以此决定是否应该将它删除。 例如,可以检査与这个条目一起存在的时间戳。
- LinkedHashSet()
- LinkedHashSet(int initialCapacity)
- LinkedHashSet(int initialCapacity, float loadFactor)
用给定的容量和填充因子构造一个空链接散列集。
EmumSet
EmimSet 是一个枚举类型元素集的高效实现。 由于枚举类型只有有限个实例, 所以EnumSet 内部用位序列实现。如果对应的值在集中, 则相应的位被置为 1。
EnumSet 类没有公共的构造器。可以使用静态工厂方法构造这个集:
1 | enum Weekday { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY }; |
可以使用 Set 接口的常用方法来修改 EnumSet。
- static < E extends Enum
>EnumSet allOf(Class enumType)
返回一个包含给定枚举类型的所有值的集。- static < E extends Enum
> EnumSet noneOf(Class< E> enumType)
返回一个空集,并有足够的空间保存给定的枚举类型所有的值。- static < E extends Enum
> EnumSet range(E from, E to)
返回一个包含 from 〜 to 之间的所有值(包括两个边界元素)的集。- static < E extends Enum
> EnumSet of(E value) - static <E extends Enum
> EnumSet of(E value, E… values)
返回包括给定值的集。
hashmap
key不可以重复,value可以重复。它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
//遍历
staff.forEach((k, v) ->
System.out.println(“key=” + k + “ value:” + v));• HashMap()
• HashMap(int initialCapacity)
• HashMap(int initialCapacity, float loadFactor)
用给定的容量和装填因子构造一个空散列映射(装填因子是一个 0.0 〜 1.0 之间的数
值。这个数值决定散列表填充的百分比。一旦到了这个比例, 就要将其再散列到更大
的表中)。默认的装填因子是 0.75。
treemap
TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
• TreeMap()
为实现 Comparable 接口的键构造一个空的树映射。
• TreeMap(Comparator<? super K> c)
构造一个树映射, 并使用一个指定的比较器对键进行排序。
• TreeMap(Map<? extends K , ? extends V> entries)
构造一个树映射, 并将某个映射中的所有条目添加到树映射中。
• TreeMap(SortedMap<? extends K, ? extends V> entries)
构造一个树映射, 将某个有序映射中的所有条目添加到树映射中, 并使用与给定的有序映射相同的比较器。
EnumMap
EnumMap 是一个键类型为枚举类型的映射。 它可以直接且高效地用一个值数组实现。在使用时, 需要在构造器中指定键类型:
1 | EnumMap<Weekday, Employee〉personlnCharge = new EnumMapo(Weekday.class); |
EnumMap(Class
keyType)
构造一个键为给定类型的空映射。
linkedhashmap
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
链接散列映射将用访问顺序, 而不是插入顺序, 对映射条目进行迭代。每次调用 get 或 put, 受到影响的条目将从当前的位置删除, 并放到条目链表的尾部(只有条目在链表中的位置会受影响, 而散列表中的桶不会受影响。一个条目总位于与键散列码对应的桶中)。要项构造这样一个的散列映射表, 请调用
1 | LinkedHashMap<K, V>(initialCapacity, loadFactor, true) |
访问顺序对于实现高速缓存的“ 最近最少使用” 原则十分重要。例如, 可能希望将访问
频率高的元素放在内存中, 而访问频率低的元素则从数据库中读取。当在表中找不到元素项
且表又已经满时, 可以将迭代器加入到表中, 并将枚举的前几个元素删除掉。这些是近期最
少使用的几个元素。
甚至可以让这一过程自动化。即构造一个LinkedHashMap 的子类,然后覆盖下面这个方法:
1 | protected boolean removeEldestEntry(Map.Entry<K, V> eldest) |
每当方法返回 true 时, 就添加一个新条目,从而导致删除 eldest 条目。例如,下面的高
速缓存可以存放 100 个元素:
1 | Map<K, V> cache = new |
另外,还可以对 eldest 条目进行评估,以此决定是否应该将它删除。 例如,可以检査与这个条目一起存在的时间戳。
- LinkedHashMap()
- LinkedHashMap(int initialCapacity)
- LinkedHashMap(int initialCapacity, float loadFactor)
- LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
用给定的容量、 填充因子和顺序构造一个空的链接散列映射表。accessOrder 参数为 true 时表示访问顺序, 为 false 时表示插入顺序。- protected boolean removeEldestEntry(Map.Entry<K, V > eldest)
如果想删除 eldest 元素, 并同时返回 true, 就应该覆盖这个方法。eldest 参数是预期要删除的条目。这个方法将在条目添加到映射中之后调用。其默认的实现将返回 false。即在默认情况下,旧元素没有被删除。然而, 可以重新定义这个方法, 以便有选择地返回 true。例如, 如果最旧的条目符合一个条件, 或者映射超过了一定大小, 则返回true。
WeakHashMap
设计 WeakHashMap 类是为了解决一个有趣的问题。 如果有一个值,对应的键已经不再使用了, 将会出现什么情况呢? 假定对某个键的最后一次引用已经消亡,不再有任何途径引用这个值的对象了。但是, 由于在程序中的任何部分没有再出现这个键, 所以, 这个键 / 值对无法从映射中删除。为什么垃圾回收器不能够删除它呢? 难道删除无用的对象不是垃圾回收器的工作吗?
遗憾的是, 事情没有这样简单。 垃圾回收器跟踪活动的对象。只要映射对象是活动的,其中的所有桶也是活动的, 它们不能被回收。 因此, 需要由程序负责从长期存活的映射表中删除那些无用的值。 或者使用WeakHashMap 完成这件事情。 当对键的唯一引用来自散列条目时, 这一数据结构将与垃圾回收器协同工作一起删除键 / 值对。
下面是这种机制的内部运行情况。WeakHashMap 使用弱引用 (weak references) 保存键。WeakReference 对象将引用保存到另外一个对象中, 在这里, 就是散列键。 对于这种类型的对象, 垃圾回收器用一种特有的方式进行处理。通常, 如果垃圾回收器发现某个特定的对象已经没有他人引用了, 就将其回收。然而, 如果某个对象只能由 WeakReference 引用, 垃圾回收器仍然回收它,但要将引用这个对象的弱引用放人队列中。WeakHashMap 将周期性地检查队列, 以便找出新添加的弱引用。一个弱引用进人队列意味着这个键不再被他人使用, 并且已经被收集起来。于是, WeakHashMap 将删除对应的条目。
- WeakHashMap()
- WeakHashMap(int initialCapacity)
- WeakHashMap(int initialCapacity, float loadFactor)
用给定的容量和填充因子构造一个空的散列映射表。
IdentifyHashMap
类 IdentityHashMap 有特殊的作用。 在这个类中, 键的散列值不是用 hashCode 函数计算的, 而是用 System.identityHashCode 方法计算的。 这是 Object.hashCode 方法根据对象的内存地址来计算散列码时所使用的方式。 而且, 在对两个对象进行比较时, IdentityHashMap 类使用 ==, 而不使用 equals。
也就是说, 不同的键对象, 即使内容相同, 也被视为是不同的对象。 在实现对象遍历算法 (如对象串行化)时, 这个类非常有用, 可以用来跟踪每个对象的遍历状况。
- IdentityHashMap()
- IdentityHashMap(int expectedMaxSize)
构造一个空的标识散列映射集,其容量是大于 1.5 * expectedMaxSize 的 2 的最小次幂
(expectedMaxSize 的默认值是 21 )。
ArrayDeque
数组实现双端队列,实现了Deque接口,链表实现是linkedlist。
• ArrayDeque( )
• ArrayDeque( 1nt initialCapacity)用初始容量 16 或给定的初始容量构造一个无限双端队列。
PriorityQueue
优先级队列
• PriorityQueue()
• PriorityQueue(int initialCapacity)
构造一个用于存放 Comparable 对象的优先级队列。
• Pr1orityQueue(int initialCapacity, Comparator <? super E> c)
构造一个优先级队列, 并用指定的比较器对元素进行排序。
集合工具类
Collections:集合框架的工具类。里面定义的都是静态方法。
Collections和Collection有什么区别?
Collection是集合框架中的一个顶层接口,它里面定义了单列集合的共性方法。
Collections是集合框架中的一个工具类,就如同Arrays是数组的工具类,该类中的方法都是静态的。
提供的方法中有可以对list集合进行排序,二分查找等方法。
通常常用的集合都是线程不安全的。因为要提高效率。
如果多线程操作这些集合时,可以通过该工具类中的同步方法,将线程不安全的集合,转换成安全的。
1 | Collections.reverse(numbers);//使list中的数据反转 |